먼저 저장된 txt 파일은 아래처럼 구성된다.

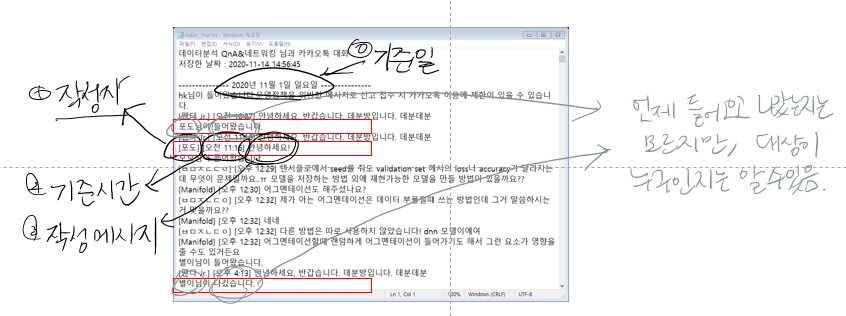
위 설명에 맞춘 정제 포인트는 아래와 같다.
- 기본 헤더 제거
- 일별 구분
- 첫 입장 메시지 제거
- 작성자/기준시간/작성 메시지 분리하기
- 입장, 퇴장 확인하기
1. 정제 전 채팅 내용 데이터(.txt) 읽기
input_file_name = 'kakao_chat.txt' # 텍스트 데이터 경로/이름 입력
with open(input_file_name, "r", encoding="utf-8-sig") as input_file:
for line in input_file:
line = line.strip()
print(line)데이터분석 QnA&네트워킹 님과 카카오톡 대화
저장한 날짜 : 2020-11-14 14:56:45
--------------- 2020년 11월 1일 일요일 ---------------
hk님이 들어왔습니다.운영정책을 위반한 메시지로 신고 접수 시 카카오톡 이용에 제한이 있을 수 있습니다.
[팬다 Jr.] [오전 10:27] 안녕하세요, 반갑습니다. 데분방입니다. 데분데분
포도님이 들어왔습니다.
[팬다 Jr.] [오전 11:16] 안녕하세요, 반갑습니다. 데분방입니다. 데분데분
[포도] [오전 11:16] 안녕하세요!
모모님이 들어왔습니다.위 블록은 코드와 결과 일부 담고 있다. 그다음에 우선적으로 해야 하는 것은 기본 헤더 제거와 일자별 내용을 묶는 것이다.
2. 기본 헤더 제외한 일자별 내용 리스트로 담기
date_sep = '일 ---------------'
context_list, tmp_context_list = [], []
with open(input_file_name, "r", encoding="utf-8-sig") as input_file:
index = 0
for line in input_file:
line = line.strip()
start_index = 4
if index == start_index:
tmp_context_list.append(line)
else:
if line.endswith(date_sep):
context_list.append(tmp_context_list)
tmp_context_list = []
tmp_context_list.append(line)
index += 1
print("주어진 텍스트 파일 {}의 일자별 context는 {}건입니다.".format(input_file_name, len(context_list)))주어진 텍스트 파일 kakao_chat.txt의 일자별 context는 11건입니다.context_list의 내용은 아래와 같다. (일부)
[['데이터분석 QnA&네트워킹 님과 카카오톡 대화', '저장한 날짜 : 2020-11-14 14:56:45', ''],
['--------------- 2020년 11월 1일 일요일 ---------------',
'hk님이 들어왔습니다.운영정책을 위반한 메시지로 신고 접수 시 카카오톡 이용에 제한이 있을 수 있습니다.',
'[팬다 Jr.] [오전 10:27] 안녕하세요, 반갑습니다. 데분방입니다. 데분데분',
'포도님이 들어왔습니다.',
'[팬다 Jr.] [오전 11:16] 안녕하세요, 반갑습니다. 데분방입니다. 데분데분',
'[포도] [오전 11:16] 안녕하세요!', (중략)1번에 비해 다소 어려워진 것 같지만 때에 따라 어려워졌을 수도 있다... ㄴㅇㄱ
전반적인 코드 아래처럼 구성되어 있다.
- 전체 내용을 담을 리스트, 일자별 내용을 담을 리스트 (각 context_list, tmp_context_list)
- 일자별 구분을 위해 사용되는 date_sep과 .endwith()
- 파일을 한 줄씩 읽는 for문, 그 한 줄에 대한 index
기본 헤더는 index 값이 0 ~ 3에 해당하므로 기준인을 index가 4로 시작된다. 그런데 기준일이 계속 늘어나기 때문에 기준일의 패턴인 [일 ---------------]을 활용하여 기준일 별 발생한 채팅 내용을 묶어줘야 한다. 그런데 첫 입장 메시지가 거슬리니 다음에서 첫 입장 메시지를 제거해본다. (단, 텍스트에 없는 경우가 있을 수 있다. 따라서 이 경우 다음을 넘어가도 된다.)
3. 첫 입장 메시지 제거하기
if ~ continue를 활용하여 첫 입장 메시지, 즉 본문에 pass_msg에 해당하면 넘어가도록 한다.
(pass와는 달리 continue는 if ~ continue 이후 코드를 실행하지 않게 해 준다.)
date_sep = '일 ---------------'
pass_msg = '운영정책을 위반한 메시지로 신고 접수 시 카카오톡 이용에 제한이 있을 수 있습니다'
context_list, tmp_contenxt_list = [], []
with open(input_file_name, "r", encoding="utf-8-sig") as input_file:
index = 0
for line in input_file:
line = line.strip()
# 새로 추가한 부분 시작
if pass_msg in line:
continue
# 새로 추가한 부분 끝
start_index = 4
if index == start_index:
tmp_contenxt_list.append(line)
else:
if line.endswith(date_sep):
context_list.append(tmp_contenxt_list)
tmp_contenxt_list = []
tmp_contenxt_list.append(line)
index += 1
print("주어진 텍스트 파일 {}의 일자별 context는 {}건입니다.".format(input_file_name, len(context_list)))[['데이터분석 QnA&네트워킹 님과 카카오톡 대화', '저장한 날짜 : 2020-11-14 14:56:45', ''],
['--------------- 2020년 11월 1일 일요일 ---------------',
'[팬다 Jr.] [오전 10:27] 안녕하세요, 반갑습니다. 데분방입니다. 데분데분',
'포도님이 들어왔습니다.',
'[팬다 Jr.] [오전 11:16] 안녕하세요, 반갑습니다. 데분방입니다. 데분데분',
'[포도] [오전 11:16] 안녕하세요!', (중략)
어느 정도 구조화 가능한 데이터를 확보했으므로 이제 본격적으로 다음 편에서 pandas를 활용해 데이터 정제 과정을 공유하고자 한다.
'Python > Community Manager를 위한 Python' 카테고리의 다른 글
| 5. 저장된 txt 파일은 어떻게 정제해야 할까? 3편 (0) | 2020.11.21 |
|---|---|
| 4. 저장된 txt 파일은 어떻게 정제해야 할까? 2편 (0) | 2020.11.21 |
| 2. 카카오톡 채팅방 대화 저장하기 (0) | 2020.11.14 |
| 1. 시작 (0) | 2020.11.14 |