2020/11/21 - [Python/Community Manager를 위한 Python] - 4. 저장된 txt 파일은 어떻게 정제해야 할까? 2편
위 링크인 이전 글에 이어서 이번 정제를 마무리를 짓도록 한다. 일단 전체 소스를 이야기 하기 전에 중요 로직을 확인해본다.
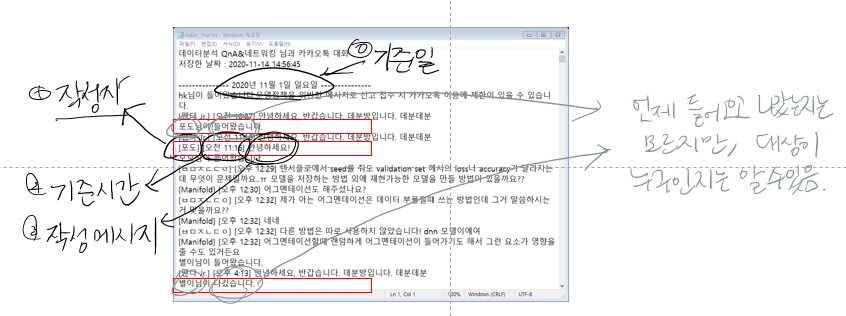
카카오톡 채팅 데이터는 line by line으로 한 메시지에 여러 문장을 작성할 경우 짤리기 때문에 같은 메시지라고 인식하고 이 메시지를 붙여주는 것이 중요하다. 먼저 1편에서 확인한 내용은 아래와 같다.
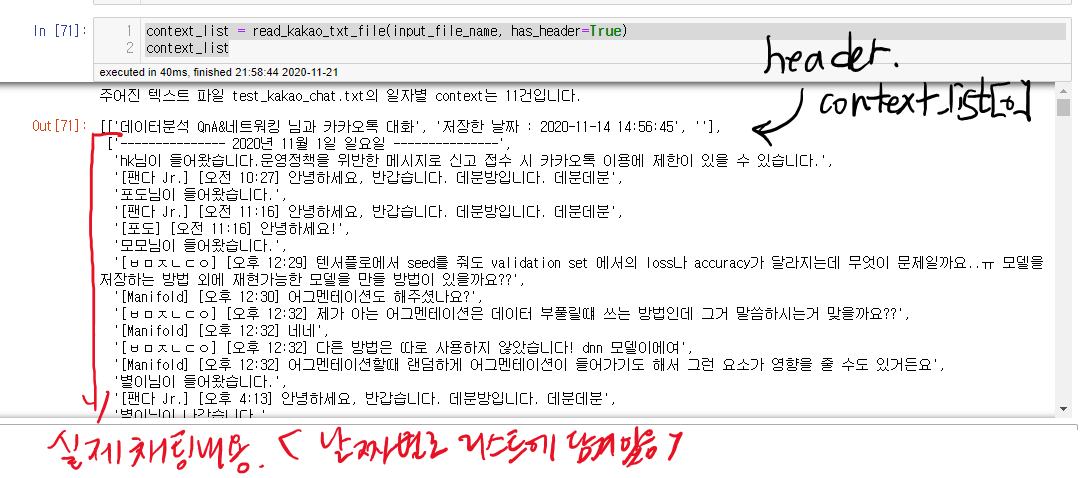
이제 아래처럼 바꿔 줘야 한다. 물론 아래는 각 채팅날짜별로 돌기 때문에 for loop를 이용하여 모든 날짜에 적용할 것이다. 그리고 아래에서 작성하진 않았지만 각 리스트로 구성된 메시지를 문자열로 변환 작업도 필요하다.

fig2 결과를 위해 사용한 함수는 아래와 같다. 채팅 날짜에 해당하는 전체 메시지를 작성자+작성시간에 맞춰 문자열로 변환 후 다시 리스트 객체에 담아준다. 크게 신경써야 하는 부분은 1) 메시지가 시작된 부분인가? 2) 이전 편에서 확인했던 관리자 행동이나 참여자의 인입인가? 이다.
def split_talk_by_user(context):
whole_txt, merge_txt = [], []
for index, element in enumerate(context):
start_str = re.match(r'\[.*?\]\s\[[오전|오후].*?\]', element)
if start_str:
whole_txt.append(' '.join(merge_txt))
merge_txt = []
merge_txt.append(element)
if index == len(context)-1:
whole_txt.append(' '.join(merge_txt))
else:
is_contain = False
for action in ACTIONS:
if action in element:
is_contain = True
if is_contain:
if merge_txt:
whole_txt.append(' '.join(merge_txt))
whole_txt.append(element)
merge_txt = []
else:
merge_txt.append(element)
return [e for e in whole_txt if e.strip()]
그래서 전체 소스 코드는 아래를 참고하길 바란다.
github.com/hyunkyungboo/kakaotalk_chat_analysis/blob/master/01_read_txt_and_data_preprocessing.py
hyunkyungboo/kakaotalk_chat_analysis
카카오톡 채팅방 분석하기. Contribute to hyunkyungboo/kakaotalk_chat_analysis development by creating an account on GitHub.
github.com
다음 편에서는 데이터를 탐색해볼 것이다.
'Python > Community Manager를 위한 Python' 카테고리의 다른 글
| 4. 저장된 txt 파일은 어떻게 정제해야 할까? 2편 (0) | 2020.11.21 |
|---|---|
| 3. 저장된 txt 파일은 어떻게 정제해야 할까? 1편 (1) | 2020.11.14 |
| 2. 카카오톡 채팅방 대화 저장하기 (0) | 2020.11.14 |
| 1. 시작 (0) | 2020.11.14 |